样本均值是统计学中考量一组数据的集中趋势的统计量之一。设x1, x2, ..., xn是总体x中的一个样本,则统计量样本均值的计算方法如下:
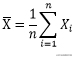
计算样本均值的公式
在r中,mean()函数用于计算样本的均值,其使用格式为:
mean(x, trim=0, na.rm = false, ...)
其中,参数x为计算对象,可以是向量、矩阵、数组或数据框;
trim用于设置计算均值前去掉两端数据的百分比,即计算结尾均值,取值在0~0.5之间;
na.rm为逻辑值,指示是否允许有缺失值(na)的情况,默认为false(不允许);
...为附加参数。

假设某班级20名学生的英语成绩为88,78,67,69,62,100,73,45,70,60,93,97,84,82,81,73,68,76,77,92。计算其均值。
编写r程序如下:
x<-c(88,78,67,69,62,100,73,45,70,60,93,97,84,82,81,73,68,76,77,92)
mean(x)
结果为76.75。如计算结尾,则:
mean(x,trim=0.05)
则结果是:77.22。
凯发官网首页的版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至598370771@qq.com举报,一经查实,本站将立刻删除。
相关文章

凌烟阁二十四功臣全介绍(凌烟阁二十四功臣排
中国为何不承认科索沃(科索沃为何不被承认)
剃须刀品牌分享(浅谈性价比高的剃须刀品牌)
商朝首都有哪些(盘点商朝的十几个首都)

历史上庚子年灾难有哪些(庚子年大事记盘点)

白马非马的真正含义(白马非马何解)
苏门四学士分别是谁(苏门四学士介绍)